
はじめに
こんにちは、ニンジンです! 前編では、自作の「価格調査ツール」が自分のブログを相手に「取得件数:0」という惨敗を喫するまでをお届けしました 。
「モダンなサイトの壁は高い……」と諦めかけたその時、私は見つけてしまったのです。HTMLという「表口」ではなく、データが整理された**「専用の裏口(API)」**の存在を 。
今回は、爆速でデータを引っこ抜く逆転劇と、自動化エンジニアとしての「最終的な着地点」についてお話しします。
救世主「WordPress REST API」の登場
多くのブログ(特にWordPress)には、外部システムとデータをやり取りするための専用窓口、**「REST API」**が標準で備わっています 。


ブラウザで開くと画像のひょうな表示がでます。
これが「REST API」です。
これを使うと、ブラウザで見える「HTML(飾り付けられた部屋)」を解析する必要がありません 。直接「データベース(整理された棚)」から、タイトルやURLを抜き出せるのです 。
APIを使った時の衝撃のシンプルコード
テストコードをクリックして表示
import requests
import openpyxl
from datetime import datetime
# WordPressの公式APIエンドポイント
API_URL = "https://py-vbalab.com/wp-json/wp/v2/posts"
print("APIからデータを直接取得中...")
# 1. データを取ってくる
response = requests.get(API_URL)
if response.status_code == 200:
posts = response.json() # 文字の羅列をPythonの「辞書型」に変換
# Excelの準備
wb = openpyxl.Workbook()
ws = wb.active
ws.append(["投稿日", "タイトル", "URL"])
for post in posts:
# JSONの中から必要な項目を抜き出す
title = post['title']['rendered']
link = post['link']
# 日付を読みやすく加工
date_raw = post['date']
date_formated = date_raw.split('T')[0] # 2026-04-06T... を 2026-04-06 に
ws.append([date_formated, title, link])
print(f"取得: {title}")
# 保存
filename = f"Quick_Report_{datetime.now().strftime('%Y%m%d')}.xlsx"
wb.save(filename)
print(f"\n✨ 完了!爆速で '{filename}' を作成しました。")
else:
print("データが取得できませんでした。")
結果:10件の記事を取得成功!
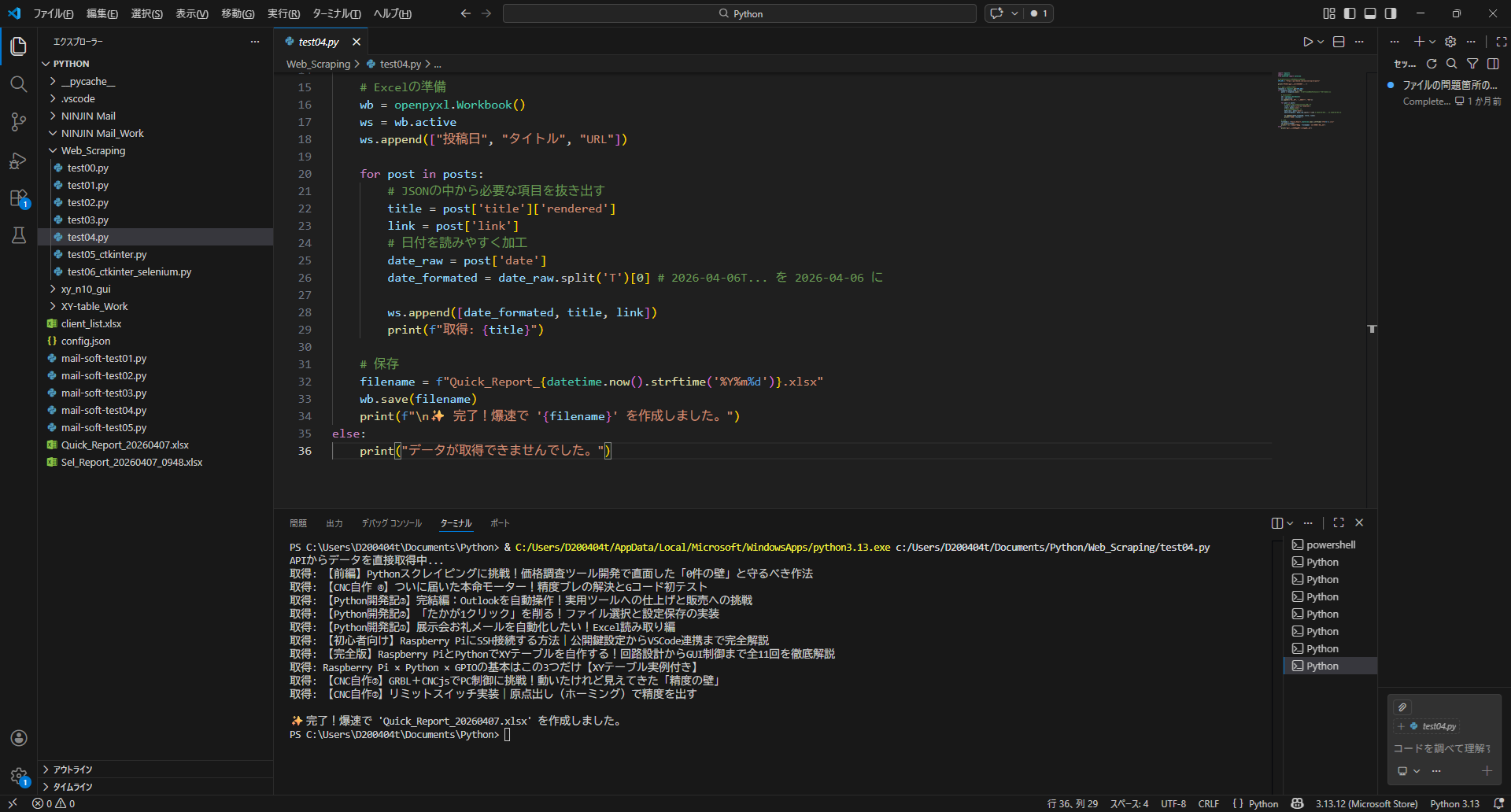
前編であれだけ苦労していたのが嘘のように記事を取得できました。
瞬時にリストが出るのは気持ちが良いですね
Webスクレイピングソフト NINJIN Edition (何とか形に)
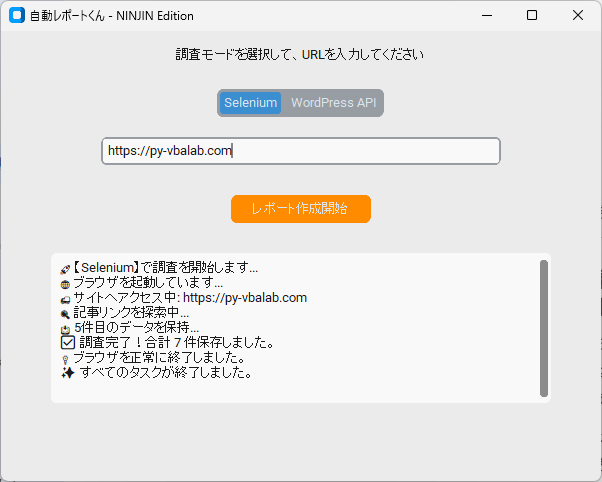
ただコードを書くだけでは「ツール」とは呼べません。 VBAユーザーにも馴染み深い CustomTkinter を使い、誰でも直感的に操作できるGUIを実装しました。
今回のツールの目玉は、用途に合わせて調査モードを瞬時に切り替えられる点です。
- WordPress APIモード:
ターゲットがWordPressサイトなら迷わずこれ。HTMLの解析が不要なため、爆速かつ100%正確にデータを抽出できます。 - Seleniumモード:
APIが提供されていない汎用サイト向けの最終手段。実際にブラウザを動かすため、JavaScriptで描画される動的サイトにも対応可能です。
Threading(マルチスレッド)の実装
このツール、実は裏側で**「スレッド」**という技術を使っています。
VBAで重い処理を実行すると、Excelが「応答なし」で固まってしまった経験はありませんか?Pythonの threading を使えば、**「裏で黙々と作業する人」と「画面を動かし続ける人」**を分けることができます。
これにより、スクレイピングの最中でもログがリアルタイムで流れ、ユーザーを不安にさせません。
Pythonコード(Full)
コードをクリックして表示
import customtkinter as ctk
import threading
import requests
import openpyxl
from datetime import datetime
import time
import os # ファイル保存確認用
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
class NinjinScraperApp(ctk.CTk):
def __init__(self):
super().__init__()
self.title("自動レポートくん - NINJIN Edition")
self.geometry("600x450")
# --- レイアウト設定 ---
self.label = ctk.CTkLabel(self, text="調査モードを選択して、URLを入力してください")
self.label.pack(pady=10)
# モード選択(セグメントボタン)
self.mode_var = ctk.StringVar(value="Selenium")
self.mode_switch = ctk.CTkSegmentedButton(self,
values=["Selenium", "WordPress API"],
variable=self.mode_var)
self.mode_switch.pack(pady=10)
self.url_entry = ctk.CTkEntry(self, placeholder_text="https://...", width=400)
self.url_entry.pack(pady=10)
self.btn_run = ctk.CTkButton(self, text="レポート作成開始",
fg_color="#FF8C00", # 人参オレンジ
command=self.start_task)
self.btn_run.pack(pady=20)
self.log_box = ctk.CTkTextbox(self, width=500, height=150)
self.log_box.pack(pady=10)
def start_task(self):
# メインスレッドが止まらないように別スレッドで実行
thread = threading.Thread(target=self.run_scraping)
thread.start()
def run_scraping(self):
mode = self.mode_var.get()
url = self.url_entry.get() #self.url_entry(GUIで入力されたURL)からURLを取得
if not url.startswith("http"):
self.update_log("⚠️ 有効なURLを入力してください。")
return
self.update_log(f"🚀 【{mode}】で調査を開始します...")
if mode == "WordPress API":
self.run_api_logic(url) # ← WordPress API版を呼び出す urlを引数として渡す
else:
self.run_selenium_logic(url) # ← ここでSelenium版を呼び出す urlを引数として渡す
self.update_log("✨ すべてのタスクが終了しました。")
def run_api_logic(self, target_url):
"""
WordPress REST APIを使用してデータを抜くロジック
"""
# 末尾に /wp-json/wp/v2/posts を付与(入力URLの整形)
base_url = target_url.rstrip('/')
api_endpoint = f"{base_url}/wp-json/wp/v2/posts"
try:
self.update_log(f"🔗 接続中: {api_endpoint}")
response = requests.get(api_endpoint, timeout=10)
if response.status_code == 200:
posts = response.json()
# Excelの準備
wb = openpyxl.Workbook()
ws = wb.active
ws.append(["投稿日", "タイトル", "URL"])
for post in posts:
title = post['title']['rendered']
link = post['link']
date_raw = post['date']
date_formated = date_raw.split('T')[0]
ws.append([date_formated, title, link])
self.update_log(f"📖 取得成功: {title[:20]}...") # 長いので省略表示
# 保存処理
filename = f"API_Report_{datetime.now().strftime('%Y%m%d_%H%M')}.xlsx"
wb.save(filename)
self.update_log(f"✅ 保存完了: {filename}")
self.show_finish_message(filename)
else:
self.update_log(f"❌ エラー: ステータスコード {response.status_code}")
self.update_log("※WordPressサイトではないか、APIが閉じられている可能性があります。")
except Exception as e:
self.update_log(f"⚠️ 想定外のエラー: {str(e)}")
def update_log(self, message):
"""ログボックスに文字を出す補助関数"""
self.log_box.insert("end", f"{message}\n")
self.log_box.see("end") # 常に最新の行を表示
def show_finish_message(self, filename):
"""完了通知(人参くんらしいメッセージ)"""
from tkinter import messagebox
messagebox.showinfo("調査完了", f"レポートの作成が終わりました!\nファイル名: {filename}")
def run_selenium_logic(self, target_url):
"""
Seleniumを使用して汎用的にデータを抜くロジック
"""
options = Options()
# ユーザーに動きを見せたい場合は headless を False に、
# 裏でこっそり動かしたい場合は True にします
options.add_argument('--headless')
driver = None
try:
self.update_log("🌐 ブラウザを起動しています...")
driver = webdriver.Chrome(options=options)
self.update_log(f"🚚 サイトへアクセス中: {target_url}")
driver.get(target_url)
# ページ読み込みと遅延読み込み対策
time.sleep(5)
driver.execute_script("window.scrollTo(0, 800);")
time.sleep(2)
self.update_log("🔍 記事リンクを探索中...")
links = driver.find_elements(By.TAG_NAME, "a")
wb = openpyxl.Workbook()
ws = wb.active
ws.append(["取得日", "タイトル", "URL"])
memo_urls = set()
count = 0
# ドメイン名を取得してフィルタリングに使用
from urllib.parse import urlparse
domain = urlparse(target_url).netloc
for link in links:
url = link.get_attribute("href")
text = link.text.strip()
# 自分のサイト内のリンクで、かつテキストがある程度長いものを抽出
if url and text and domain in url and url not in memo_urls:
if len(text) > 10: # 短すぎるリンク(「ホーム」など)を除外
clean_title = text.split('\n')[0]
ws.append([datetime.now().strftime('%Y-%m-%d'), clean_title, url])
memo_urls.add(url)
count += 1
if count % 5 == 0: # 5件ごとにログを更新
self.update_log(f"📥 {count}件目のデータを保持...")
# 保存
filename = f"Sel_Report_{datetime.now().strftime('%Y%m%d_%H%M')}.xlsx"
wb.save(filename)
self.update_log(f"✅ 調査完了!合計 {count} 件保存しました。")
self.show_finish_message(filename)
except Exception as e:
self.update_log(f"❌ Seleniumエラー: {str(e)}")
finally:
if driver:
driver.quit()
self.update_log("🔌 ブラウザを正常に終了しました。")
if __name__ == "__main__":
app = NinjinScraperApp()
app.mainloop()
ロジックの心臓部(コード解説)
今回実装したクラス NinjinScraperApp の中身を少し覗いてみましょう。
# モードに応じて呼び出す関数をバトンタッチ
if mode == "WordPress API":
self.run_api_logic(url)
else:
self.run_selenium_logic(url)
GUIで入力されたURLは、引数としてそれぞれのロジックへリレーされます。
- API版:
requestsでJSONデータを取得し、辞書型データからタイトルやURLをスマートに抽出。 - Selenium版:
driver.find_elementsでページ内のリンク(aタグ)を全走査。ドメイン一致などのフィルタリングをかけて、ゴミのないリストを作成します。
どちらのモードでも、最終的には使い慣れた Excelファイル(.xlsx) として保存される仕組みです。
なぜ「ECサイトの価格調査」を断念したのか?
あれ?っと思った方もいらっしゃると思います
実は、当初の目的だった「ECサイトの価格調査」の実装は最終的に見送りました 。
理由はシンプルです。
👉 「やろうと思えばできるが、やるべきではない」と判断したためです。
- メンテナンスの限界: 大手サイトは構造変更が激しく、昨日のコードが今日動かなくなる「いたちごっこ」になり、個人での運用は現実的ではありません
- 規約と負荷: 無理なスクレイピングで負荷をかけるより、公式API(AmazonならPA-APIなど)を申請するのが、長期的には最も安全で確実です 。
結び:まずは「体験」してみよう
今回の開発記を通じて、私がたどり着いた答えはこれです。
- 正面突破(スクレイピング)がダメなら裏口(API)を探せ!
- 相手のサイトを尊重し、最適な技術を選ぶ。
- 「できること」と「やるべきこと」を切り分ける。
まずは自分のブログや気になるサイトで、 「/wp-json/wp/v2/posts」 を試してみてください。
きっと、**「スクレイピングしなくても取れる世界」**を体験できるはずです。
「自動レポートくん(NINJIN Edition)」の開発はこれにて完結。 また別の物語でお会いしましょう!
今回の教訓: 正式な窓口(API)があるならそれを使う。なければSeleniumで丁寧に。技術の使い分けこそが自動化の鍵。

コメント