
はじめに
こんにちは、ニンジンです! 普段は「初心者からのVBA-Py業務自動化ラボ」を運営していますが、今回は自動化エンジニアなら誰もが一度は憧れる**「競合サイトの価格調査自動化」**に挑みます。
Pythonの Requests や Selenium を武器に、ボタン一つで最新価格をExcelにまとめる……そんな夢のようなツール開発の裏側(と、手痛い失敗談)をお届けします。
開発前に知っておくべき「Webの作法」
スクレイピングは強力な反面、相手のサーバーに負担をかける「諸刃の剣」です。まずは絶対に譲れない3つの作法を紹介します。
① サイトの意思表示「robots.txt」を確認する
Webサイトには、**「ここはプログラム(ロボット)で入っていいよ」「ここはダメだよ」**という意思表示が書かれたファイルが存在します。それが robots.txt です。
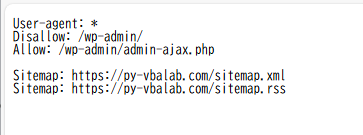
確認方法: URLの末尾に /robots.txt をつけてアクセスします。
例: https://py-vbalab.com/robots.txt
User-agent: *(すべてのロボットへ)Disallow: /admin/(管理画面へのアクセス禁止) このような記述がある場合、指定された場所へのスクレイピングは控えましょう。これはエンジニア同士の「暗黙の了解」であり、礼儀です。
② アクセス間隔(time.sleep)を確保する
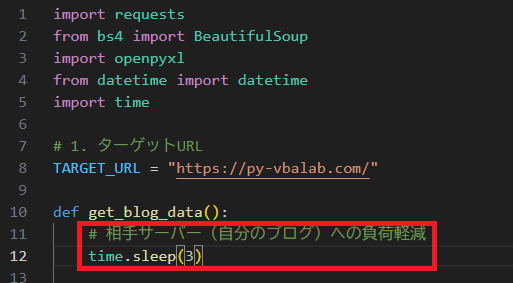
1秒間に何十回もアクセスするのは、もはや攻撃(DoS攻撃)と同じです。 import time を使い、time.sleep(3) などの待機処理を必ず入れましょう。**「1秒に1回以上のアクセスは、相手のサーバーへの攻撃になり得る」**というリスク意識を持つことが大切です。
③ 練習は「練習用サイト」で行う
いきなり一般の商用サイトで練習するのはマナー違反。まずはスクレイピング練習専用の「砂場(サンドボックス)」を使いましょう。
おすすめ練習サイト:Books to Scrape
ここはスクレイピングの練習用に公開されているサイトなので、安心してコードを試すことができます。ここで基礎を固めてから、実戦(自分のブログなど)に挑むのが王道です。
(Requests+ BeautifulSoup編)自分のブログを抜いてみる
さて、作法を学んだところで、私のブログ(https://py-vbalab.com)をターゲットに調査開始です!まずは軽量・高速な定番コンビ「Requests + BeautifulSoup」で挑みました。
RequestsとBeautifulSoupのインストール(必要に応じて)
pip install beautifulsoup4 requests
テストコード
テストコードをクリックして表示
import requests
from bs4 import BeautifulSoup
import openpyxl
from datetime import datetime
import time
# 1. ターゲットURL
TARGET_URL = "https://py-vbalab.com/"
def get_blog_data():
# 相手サーバー(自分のブログ)への負荷軽減
time.sleep(3)
try:
response = requests.get(TARGET_URL)
response.encoding = response.apparent_encoding # 文字化け防止
soup = BeautifulSoup(response.text, 'html.parser')
# 記事カードの塊を特定(WordPressなどの一般的な構造を想定)
# ※実際のHTML構造に合わせて 'entry-card' 等のクラス名は調整が必要な場合があります
articles = soup.find_all('div', class_='entry-card-content')
print(f"取得できた記事数: {len(articles)}")
data_list = []
for article in articles:
# タイトルの取得
title_tag = article.find('h2')
title = title_tag.text.strip() if title_tag else "タイトルなし"
# URLの取得
link_tag = article.find('a')
url = link_tag['href'] if link_tag else "URLなし"
# 投稿日の取得(timeタグや特定クラスのspanを想定)
date_tag = article.find('span', class_='post-date')
date_text = date_tag.text.strip() if date_tag else "日付不明"
data_list.append([date_text, title, url])
return data_list
except Exception as e:
print(f"エラーが発生しました: {e}")
return []
def save_to_excel(data):
# Excel新規作成
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "記事リスト"
# ヘッダー
ws.append(["投稿日", "記事タイトル", "URL"])
# データの書き込み
for row in data:
ws.append(row)
# ファイル名に実行日時を付けて保存
file_name = f"BlogList_{datetime.now().strftime('%Y%m%d_%H%M')}.xlsx"
wb.save(file_name)
print(f"✅ Excelファイル '{file_name}' を作成しました!")
# 実行
if __name__ == "__main__":
print("データ取得中...")
blog_data = get_blog_data()
if blog_data:
save_to_excel(blog_data)
else:
print("データが取得できませんでした。HTML構造を確認してください。")
結果:取得できた記事数 0
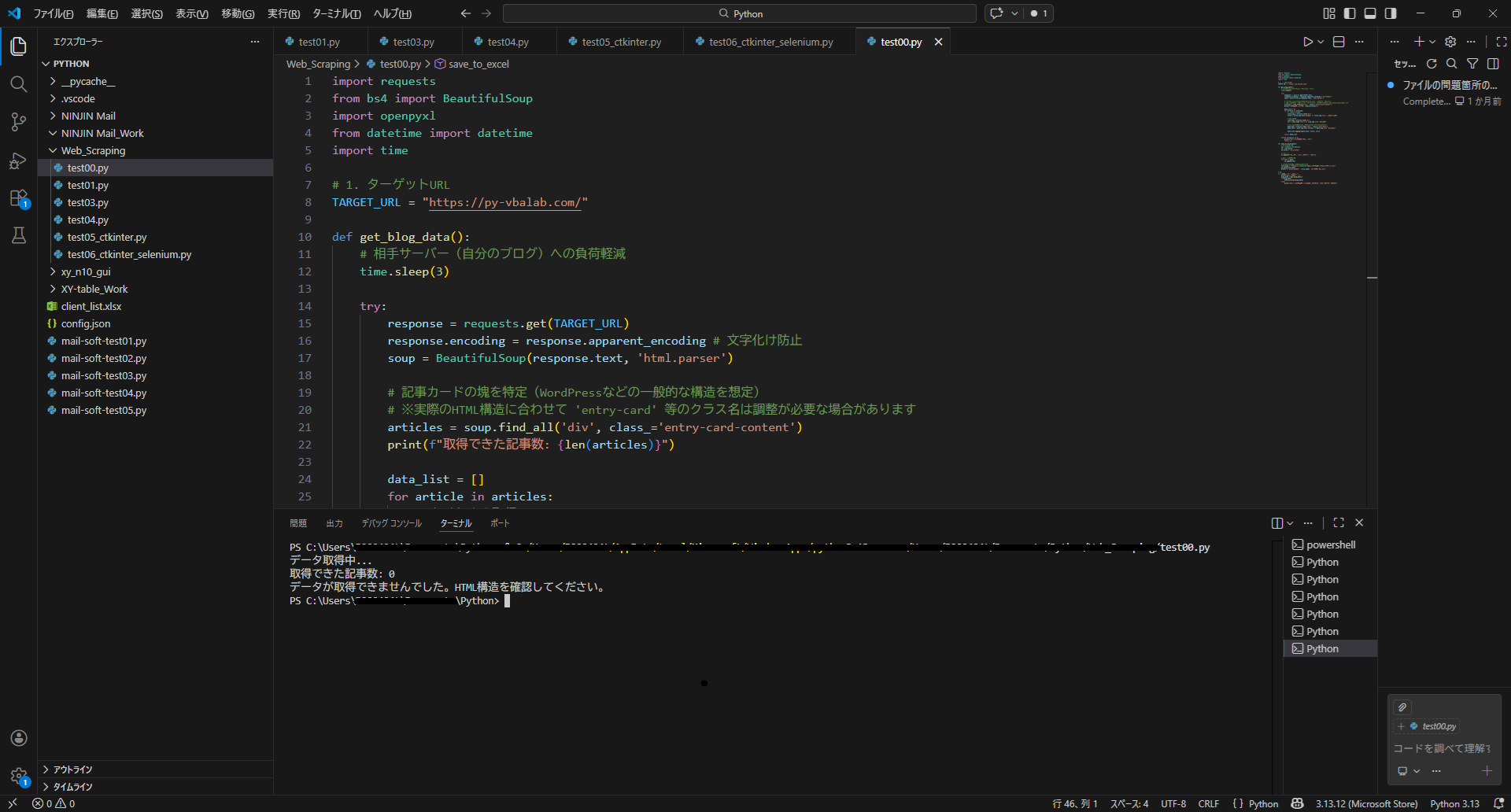
「えっ、28記事以上あるはずなのに……?」
ここで最初の壁にぶち当たりました。ブラウザでは見えているのに、Pythonからは見えない。原因は、最近のモダンなブログテーマ(SWELLなど)が採用している**「遅延読み込み(Lazy Load)」**でした。データがHTMLに直接書いておらず、JavaScriptで後から表示される仕組みだったのです。
(Selenium編)(第二の刺客)自分のブログを抜いてみる
「生身のHTMLがダメなら、本物のブラウザを動かせばいいじゃないか!」
次に投入したのは、ブラウザを自動操作する「Selenium」です。
Seleniumのインストール(必要に応じて)
pip install selenium
テストコード
テストコードをクリックして表示
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
options = Options()
driver = webdriver.Chrome(options=options)
try:
print("ブラウザを起動してアクセス中...")
driver.get("https://py-vbalab.com/")
# 読み込み待ち(10秒くらい余裕を持たせてみる)
time.sleep(8)
# --- 修正ポイント:複数の探し方を試す ---
print("要素を探しています...")
# 案A: SWELLの標準的なタイトルクラス
elements = driver.find_elements(By.CSS_SELECTOR, ".p-postList__title")
# 案B: もしAがダメなら、記事カード内のh2を全部取る
if len(elements) == 0:
elements = driver.find_elements(By.CSS_SELECTOR, "h2.post_title, .c-postitem__title, .p-postList__item h2")
print(f"取得できた記事数: {len(elements)}")
for i, el in enumerate(elements):
# 画面に映っていないとテキストが取れない場合があるので、取得方法を工夫
title = el.get_attribute("textContent").strip()
print(f"{i+1}: {title}")
finally:
print("3秒後に終了します...")
time.sleep(3)
driver.quit()
結果:取得できた記事数 0
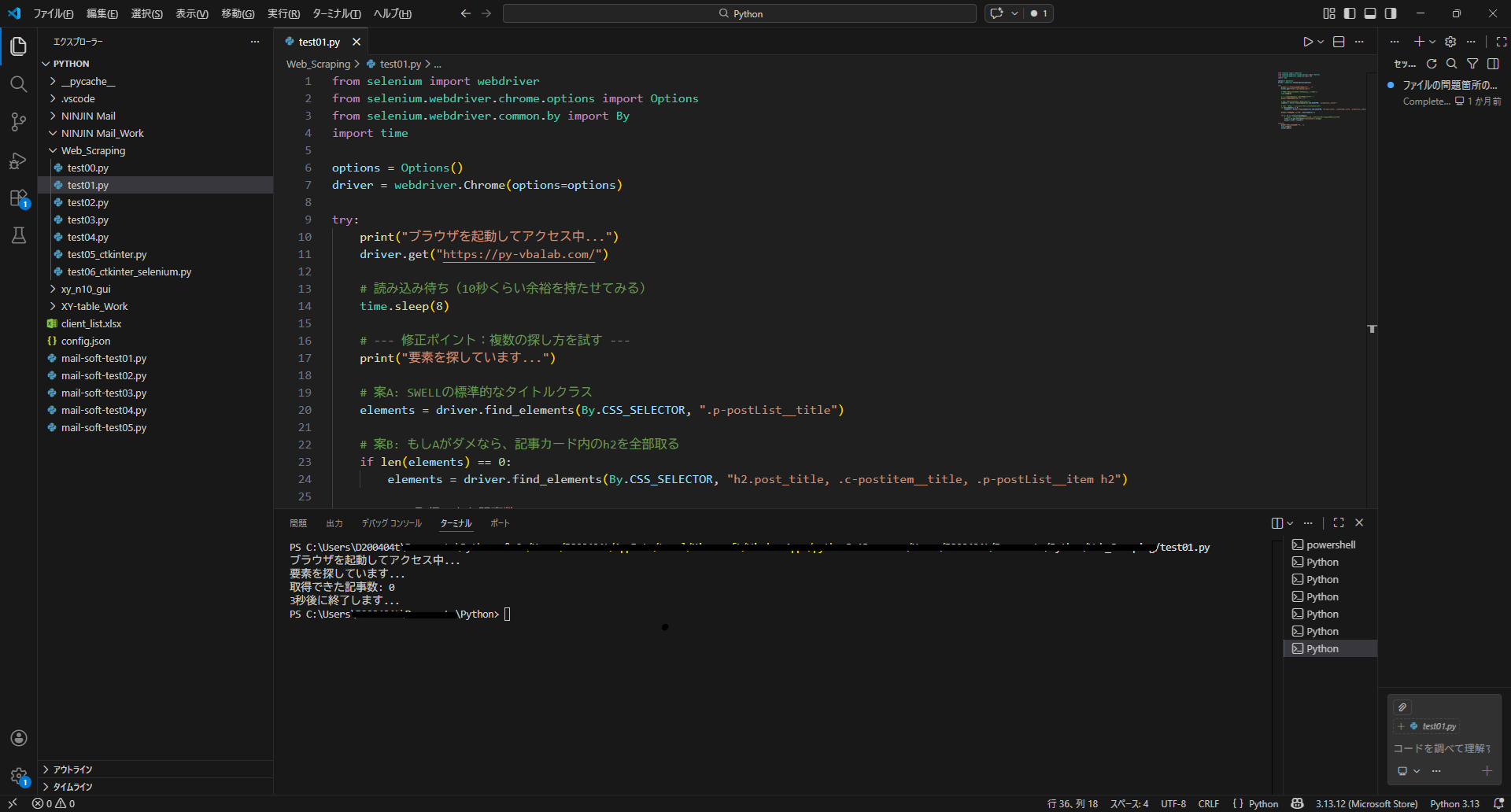
しかし、ここでも苦戦が続きます。 「クラス名が一致しない」「特定の要素が見つからない」……サイトの構造は非常に複雑で、ちょっとしたデザイン変更や高速化設定のせいで、ピンポイントで「商品名」や「価格」を抜くのがいかに難しいかを痛感しました
前編のまとめ:スクレイピングの「甘くない現実」
当初は「どんなサイトからでも価格を引っこ抜けるツール」を夢見ていましたが、現実はそう甘くありませんでした。
- サイトごとにHTMLの構造が違うため、汎用化が難しい。
- モダンなサイトはJavaScriptで後からデータを描画するため、単純な取得ができない。
- 無理なスクレイピングは、相手にとっても自分にとってもリスクがある。
- そして、常にメンテナンスし続けなければならない運用の壁
「やはり、価格調査ツールの自動化は個人では無理なのか……?」
そう諦めかけた時、「裏口」を見つけました。HTMLを解析しなくても、もっとスマートに、もっと正確にデータを抜く方法があったのです。
次回、完結編!
「スクレイピングはもう古い!?WordPress APIで実現する爆速レポート作成とエンジニアが出した正解」
お楽しみに!
今回の教訓: 正面突破(HTML解析)がダメなら、一度立ち止まって「裏口(API)」がないか探してみよう。

コメント